Changan Chen 陈昌安
|
I am a co-founder and Chief Research Officer at Rhoda AI. Previously, I was a postdoctoral researcher at Stanford University hosted by Prof. Fei-Fei Li and Prof. Ehsan Adeli. I received my PhD from UT Austin advised by Prof. Kristen Grauman. During my PhD, I was fortunate to spend a few years working as a visiting researcher at Facebook AI Research (FAIR). I am interested in building intelligent and generalizable machine learning systems that perceive and interact with the world. |
Photo credit: Jasmin Zhang |
|
|
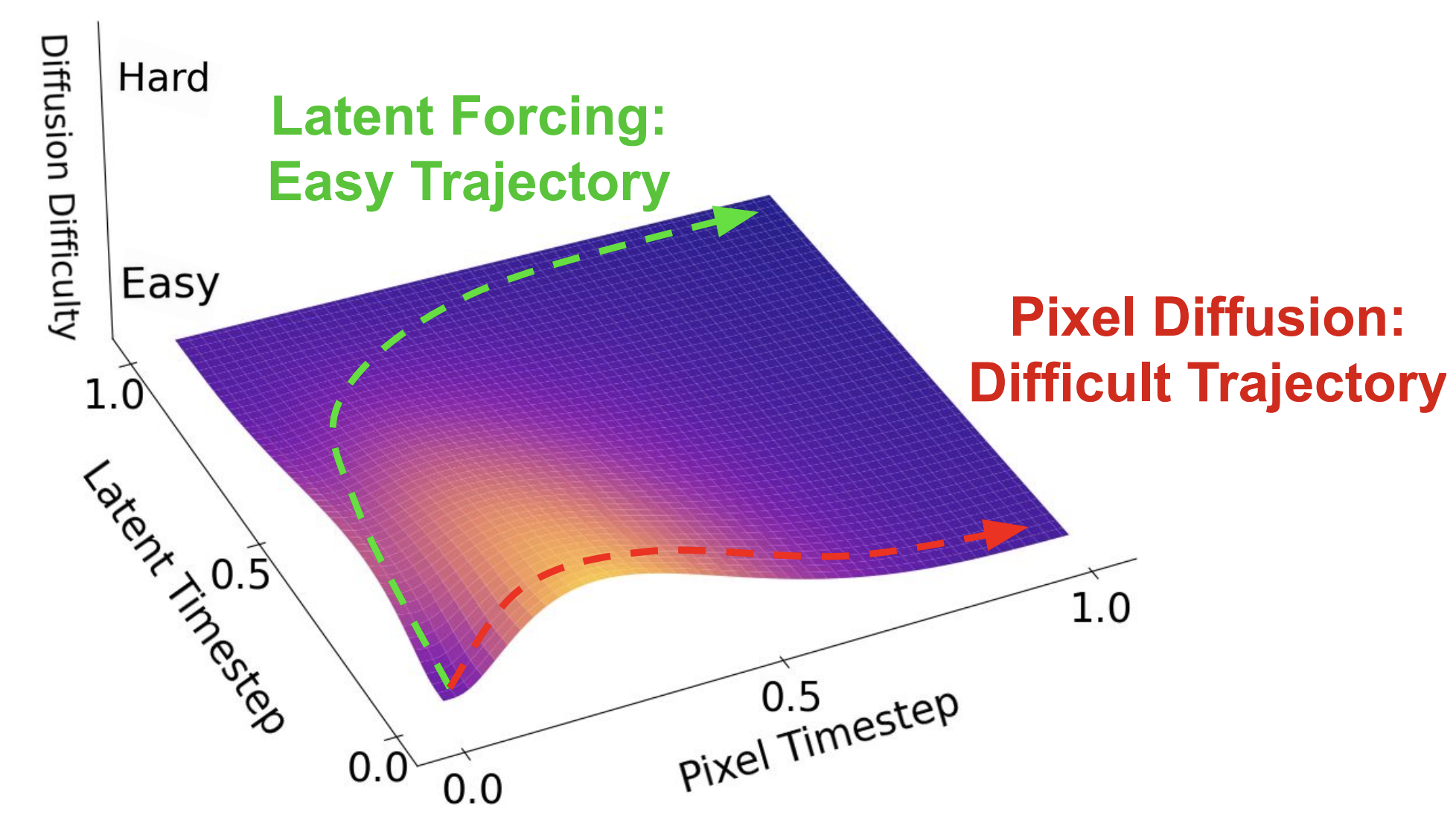
|
|
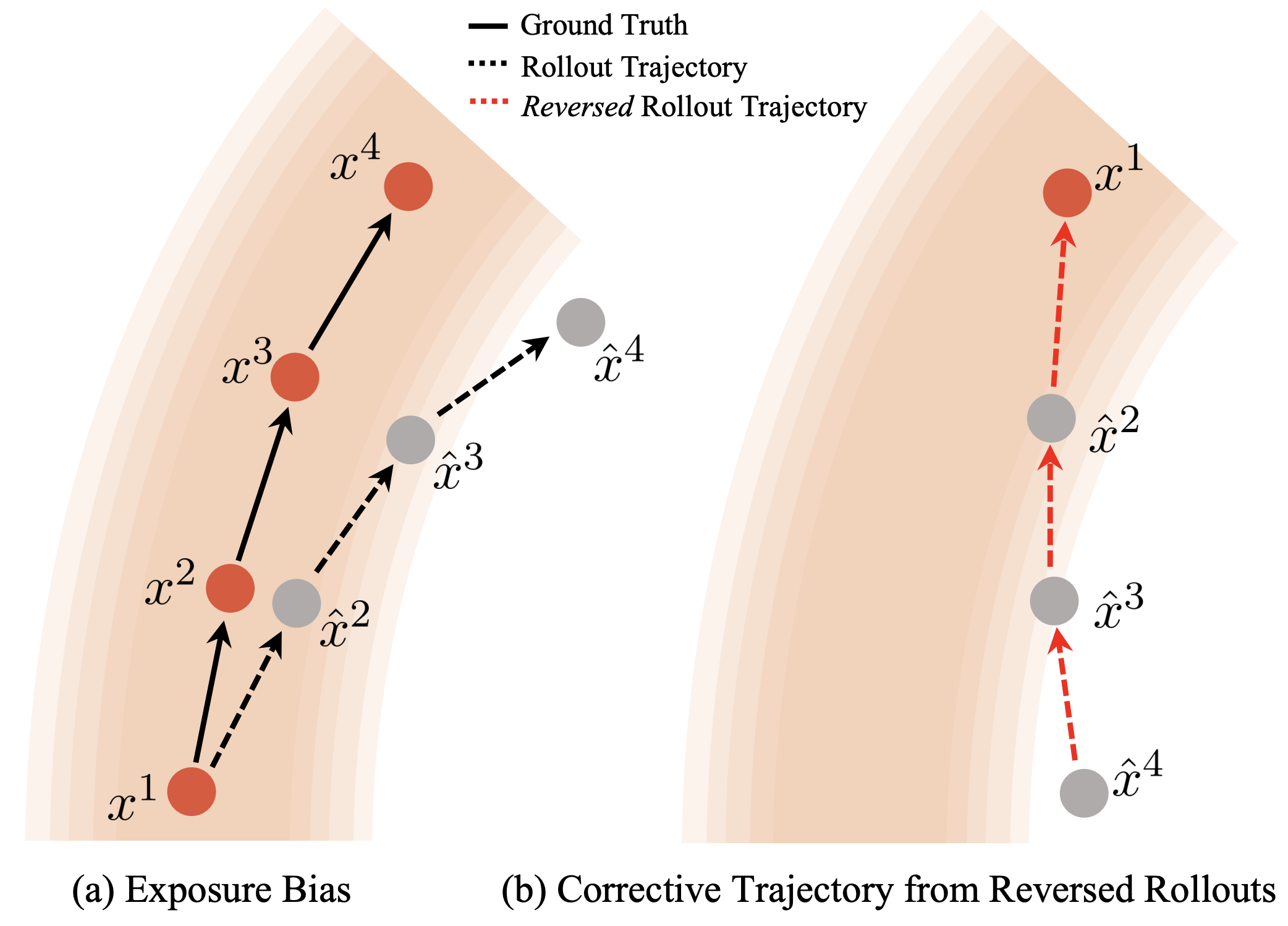
|
|
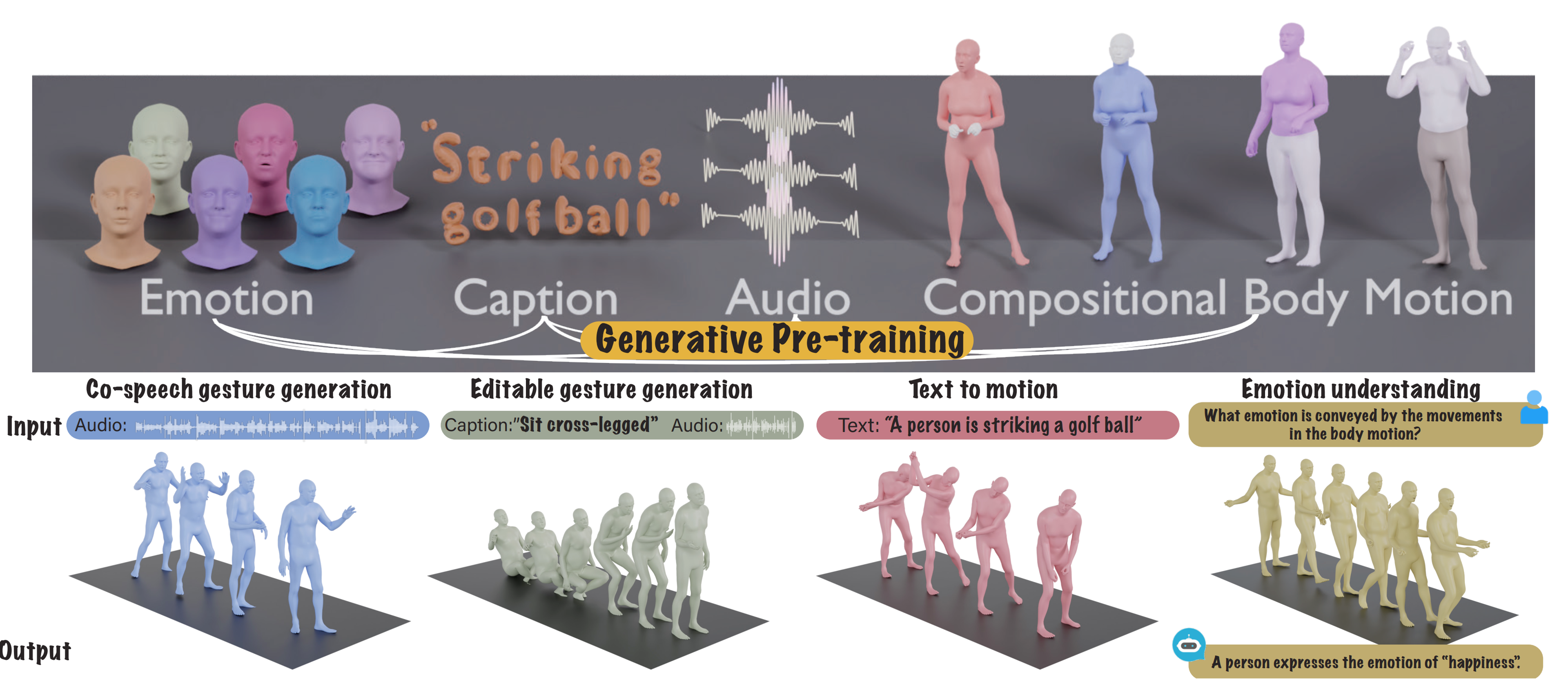
|
|

|
|
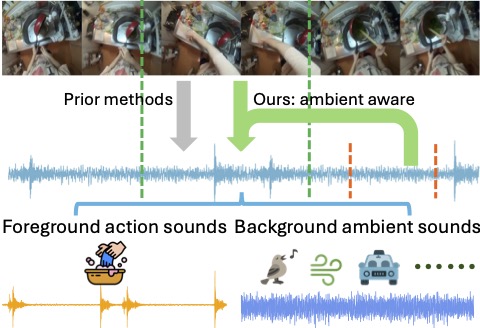
|
|
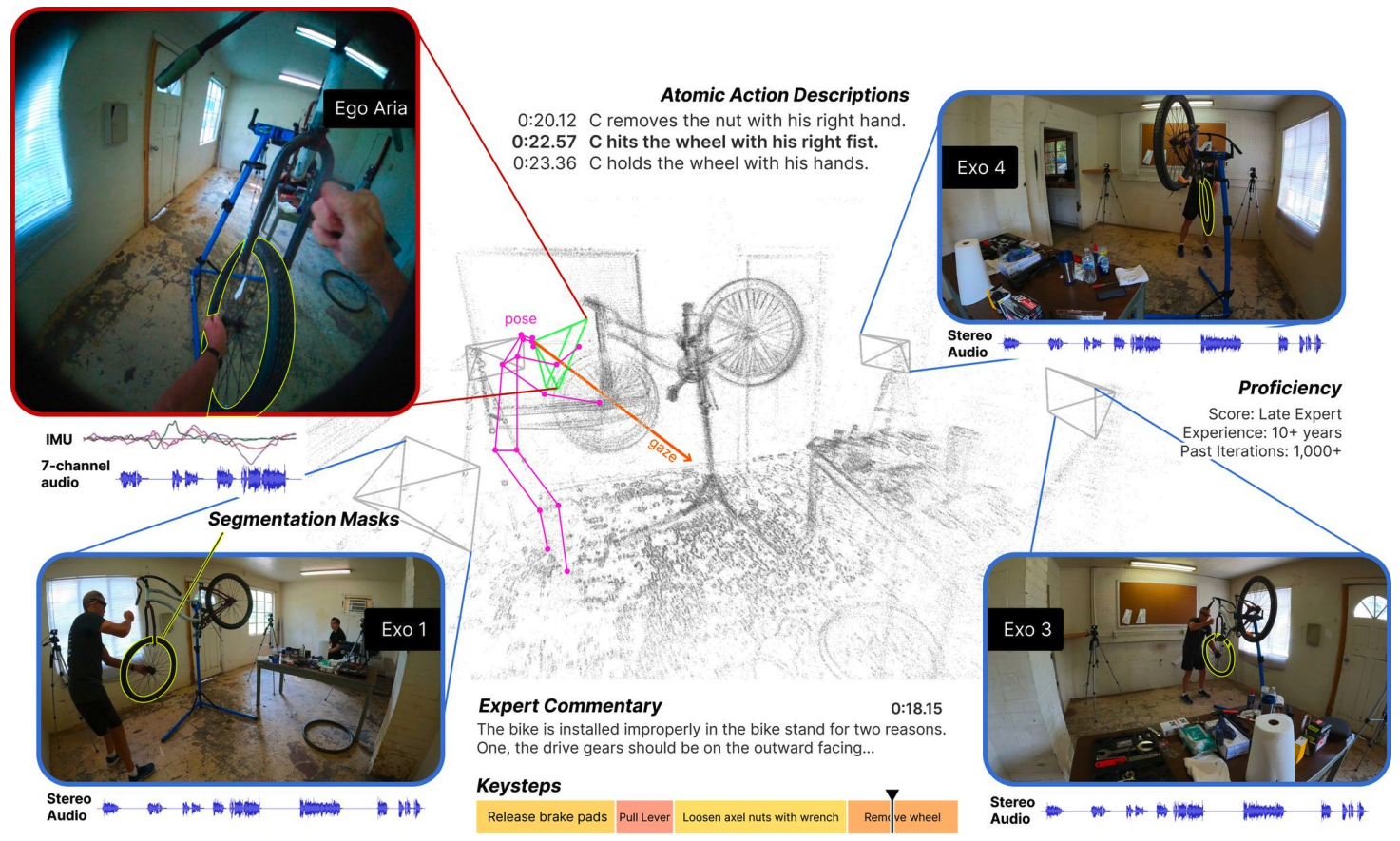
|
|
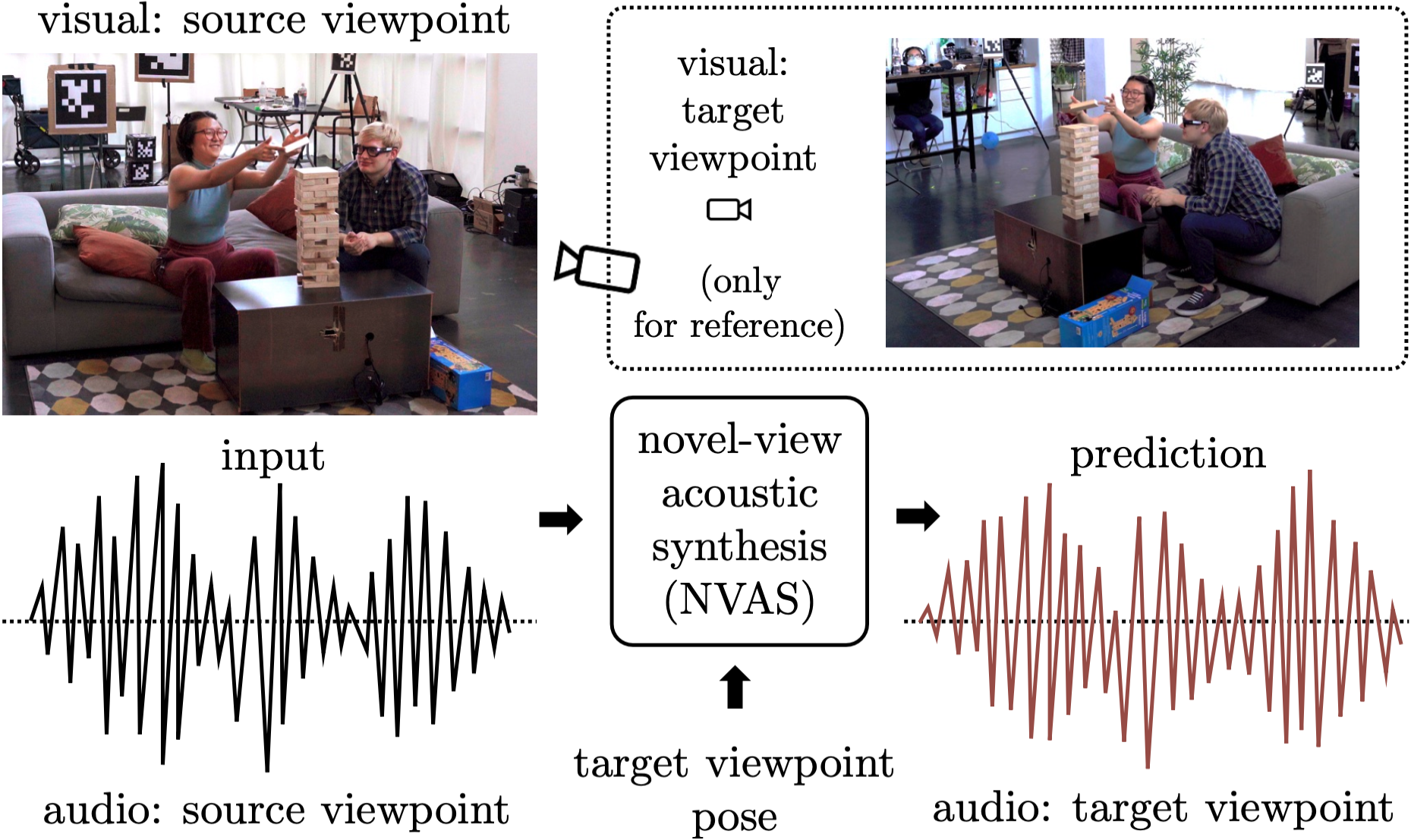
|
|
|
|
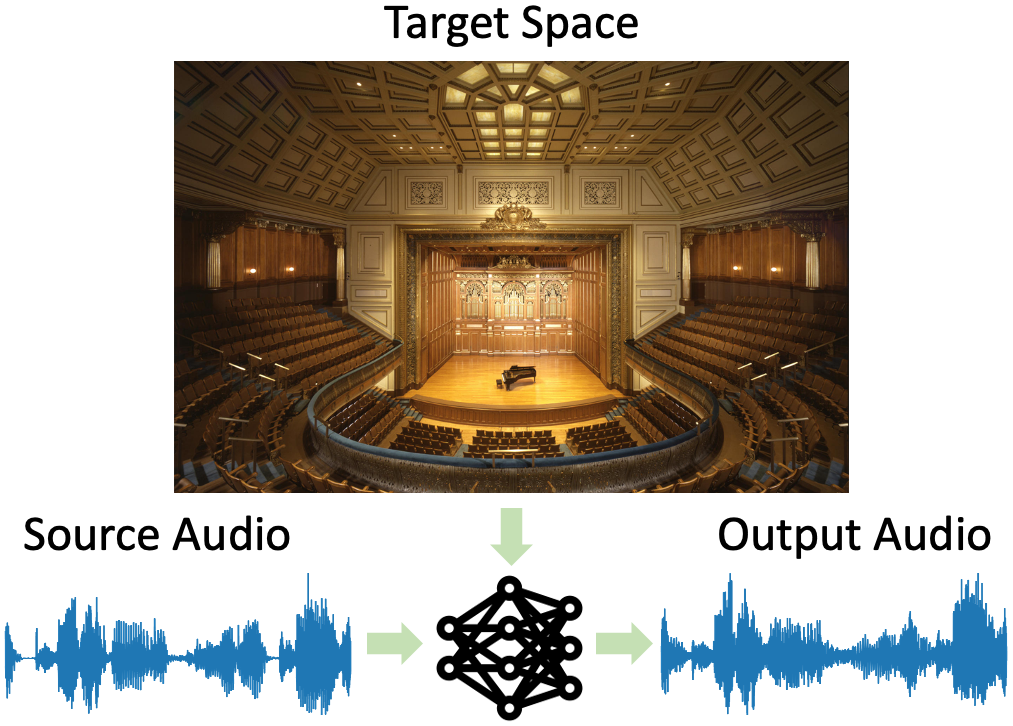
|
|
|
|
|
|
|
|
|
Last updated: March 2026 |